Machine learning as a web application
11. March 2019

Topics
Everyone is currently using buzzwords like artificial intelligence (AI) and machine learning (ML). Our data scientist can explain what they mean in simple terms. Train your own models using Predictoor, a practical web application, and the Random Forest algorithm.
What is machine learning?
Can you predict the sale price of a detached house? Which of your customers are likely to cancel their contract soon? How can you distinguish between suspicious transactions and normal bank transfers? Questions like these lead directly into the world of artificial intelligence and machine learning, in which data is turned into information.
The subgroup of supervised learning uses algorithms that analyse countless data examples to find connections between a target value and explanatory variables. After this training phase, the algorithm can apply the learned connections to new cases and thus predict the target value.
Variables
Variables explain a dataset and help the algorithm find connections.

Target variable
What do you want to predict? For example, which employees are at risk of leaving the company?
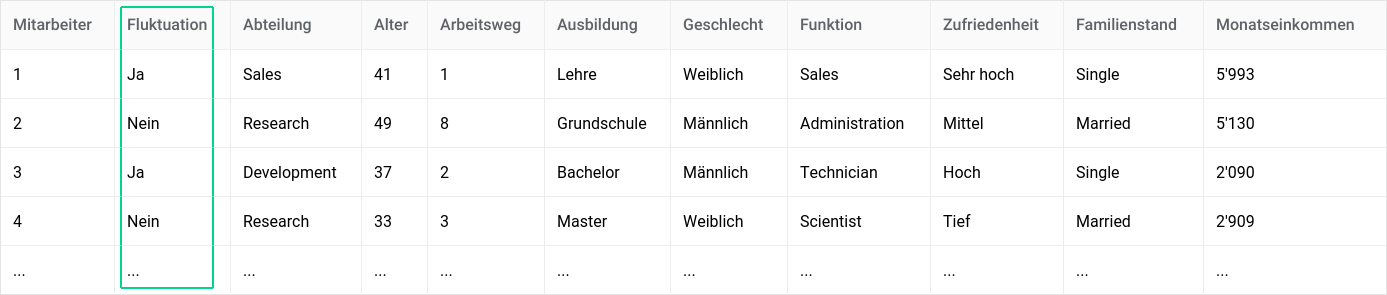
Cases
Every line is an observation. The algorithm learns from these to predict new cases.

No longer just for experts
For a long time, only specialists could develop and use complex prediction models. They tested, supplemented and transformed input data, selected a suitable model class, optimised the model parameters and validated the accuracy of their predictions. Modern algorithms and sensible preparatory steps now enable large parts of this process to be automated. The resulting models supply robust and accurate predictions – provided the data permits this.
However, the preparatory steps in particular are unavoidable and can be rather complex. In order to ensure that the learning algorithm can make exact predictions, a structured database is required. As part of this, the target variable must be defined as precisely as possible (a process known as “feature engineering”).
“Coming up with features is difficult, time-consuming, requires expert knowledge. ‘Applied machine learning’ is basically feature engineering.”
Andrew Ng
The proof of the pudding is in the eating
Perhaps you already have a dataset that describes your products, customer data or your competitors’ offers, for example, and would like to predict a key variable of this dataset with the aid of the other information. In this way, you could, for instance, estimate future sales of your products, identify and contact customers with a high cancellation risk or take a closer look at your rivals’ price models.
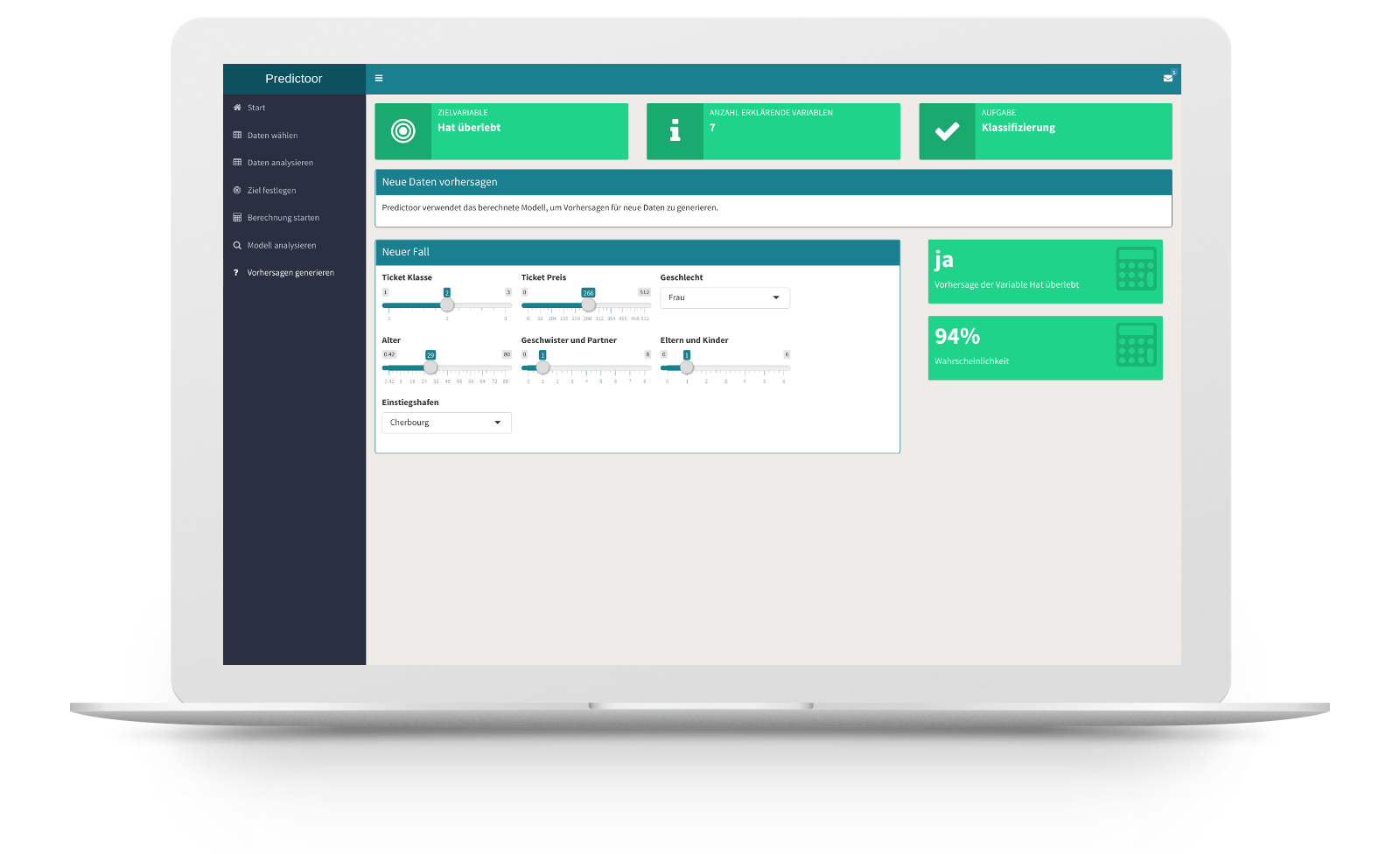
Why not give it a try? Predictoor is your artificial intelligence, learning how to predict the desired target value from your datasets on the basis of your selected information.
Predictoor
Predictoor prüft zuerst den Umfang und die Vollständigkeit Ihres Datensatzes und entscheidet, welche Variablen für die Modellierung geeignet sind. Predictoor entscheidet sich aufgrund der gewählten Zielgrösse automatisch für ein passendes Regressions- oder Klassifikationsmodell (Vorhersagen von Zahlenwerten wie z.B. Preisen oder Vorhersagen von Kategorien wie z.B. «kündigt» / «kündigt nicht»). Während der Lernphase optimiert er die Modellparameter und prüft die Modellgüte, indem er seine Vorhersagen für zuvor ausgeschlossene Datenpunkte mit den tatsächlichen Werten vergleicht (dieser wichtige Check wird Kreuzvalidierung genannt). Die Vorhersagegenauigkeit und die Wichtigkeit der einzelnen erklärenden Variablen zeigt er Ihnen verständlich auf. Schliesslich können Sie mit dem trainierten Modell Vorhersagen für neue Fälle generieren.
It’s based on a random forest
Predictoor currently learns using a well-known and powerful algorithm known as Random Forest (developed by Leo Breiman in 1999). Here, it generates countless variations of decision trees easily influenced by chance. To make a prediction, it takes the average of the results of all the individual trees. The name derives from the fact that many trees make a forest.
You can also acquaint yourself with Predictoor without your own data. A number of different sample datasets are available to help you train your first models. So let Predictoor predict the survival chances of Titanic passengers, house prices or the quality of certain wines!
Additional information
Find out what modern algorithms can do with your datasets! We’ll gladly support you in this by providing additional data, preparatory steps or specifically optimised models to enable you to turn data into information.