Predicting painting sales using computer vision and machine learning
7. April 2021
Themen
Wir unterstützten Cyrill Püntener bei seiner Semesterarbeit zum Thema Kunstbewertung mit einem Datensatz aus unserem Kunstprojekt.
Cyrill Püntener studiert im 3. Semester Informatik an der ETH Zürich. Für seine Semesterarbeit zum Thema «Data Science for Decision-Making» hat er sich auf der Suche nach einem realen Datensatz an Datahouse gewendet. Weil wir junge Talente gerne unterstützen und aktuell im Kunstbereich mit Datenanalysen experimentieren, haben wir ihm einen passenden Datensatz zur Verfügung gestellt. Wir freuen uns sehr über seine hochstehende Arbeit und seinen Erfahrungsbericht.
Was war das Ziel deiner Semesterarbeit?
Ergänzend zu einer eher theoretisch orientierten Vorlesung, sollten wir das erlernte Wissen im Rahmen einer Semesterarbeit auf realen Datensätzen praktisch anwenden. Die Vorlesung mit dem Titel «Building a Robot Judge: Data Science for Decision-Making» beschäftigte sich mit Machine Learning im Bereich von Expertenentscheidungen, also zum Beispiel mit der Schätzung von Kunstwerken.
Auf der Suche nach einem passenden Datensatz, wandte ich mich an Datahouse. Freundlicherweise konnten sie mir einen Datensatz einer weltweit tätigen Kunst-Plattform zur Verfügung stellen, wo Gemälde im tiefen Preissegment angeboten werden. Neben dem Verkaufspreis, dem Namen des Künstlers und dem Titel des Kunstwerkes, enthielt der Datensatz noch viele weitere öffentlich zugängliche Metadaten zu den Kunstwerken. Ziel meiner Arbeit war es mithilfe von Machine Learning vorauszusagen, ob ein Bild zu gegebenem Verkaufspreis auch effektiv verkauft wird.
Wie hast du dich in das Thema Kunstbewertung eingearbeitet?
Als ETH Student war mir die Welt der Kunstbewertung zu Beginn meiner Arbeit ziemlich fremd, umso wichtiger ist es sich entsprechend einzulesen. So habe ich einige wissenschaftliche Paper zum Thema gelesen, den «Global Art Market Report» der Art Basel und der UBS studiert und mich über Umwege mit einem Kunststudenten aus Venedig ausgetauscht. Dieser erzählte mir, dass er den Verkaufspreis seiner Kunstwerke mit folgender Daumenregel festlegt:
Preis in Euro ≈ (Höhe in cm + Breite in cm) * Karrierestufe
Wobei Karrierestufe einer Zahl zwischen 10 für Studenten, 20 für Künstler ohne Vertretung und 25 beim Verkauf über eine Galerie entspricht. Für bekannte Künstler ist dem Wert der Karrierestufe keine Grenze gesetzt.
Mit welchen Methoden hast du dich mit dem Datensatz vertraut gemacht?
In einem ersten Schritt habe ich versucht, jeden Parameter zu verstehen. Welche Daten habe ich überhaupt zur Verfügung? Wie wurden diese erhoben? Dazu gehört auch zu recherchieren, wie beispielsweise Kunstwerke auf der Plattform erfasst und behandelt werden.
Wichtig ist in diesem Schritt auch eine Qualitätskontrolle der einzelnen Features zu machen. So stellt sich beispielsweise heraus, dass der Durchschnitt aller Bewertungen bei 4.9 von 5 Sternen lag. Negative Bewertungen gab es so gut wie keine. Für meine weitere Untersuchung hiess dies, die Künstlerbewertung ist wertlos.
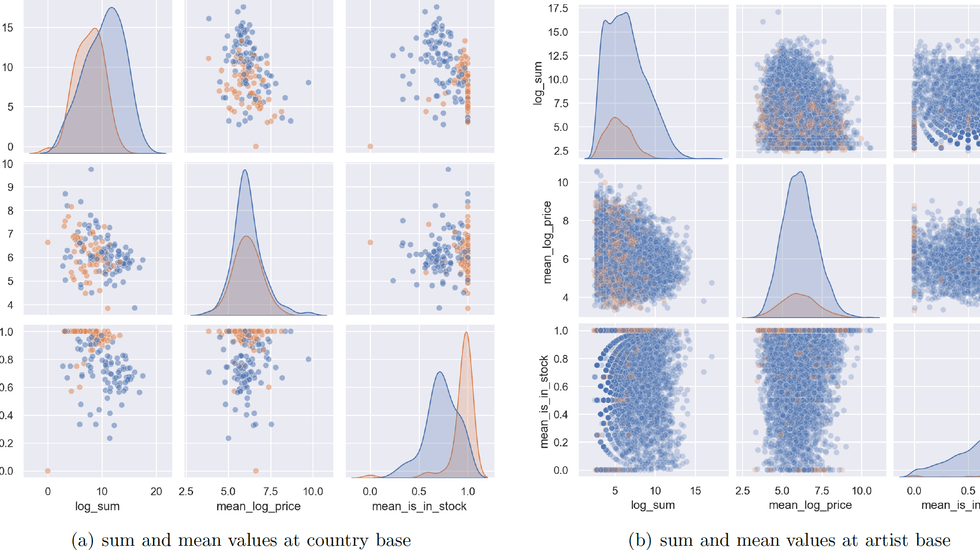
In einem zweiten Schritt ging es darum Zusammenhänge zwischen den Features zu finden und zu analysieren. Hierbei ist Ausprobieren das A und O. So habe ich unzählige Tabellen, Grafen und Grafiken erstellt. Daraus entstand auch die folgende Übersicht, die den Zusammenhang zwischen dem durchschnittlichen Preis (mean_log_price), der Anzahl Bilder (log_sum) und dem Anteil der verkauften Kunstwerke (mean_is_in_stock) eines Landes (a) bzw. pro Künstler (b) zeigt. Solche Grafiken helfen ein vertieftes Verständnis des Datensatzes zu erlangen.
Welche Machine Learning Modelle hast du eingesetzt und wie hast du diese ausgewählt?
Grundsätzlich habe ich zwei Typen von Modellen auf den Datensatz losgelassen. Modelle des Typ I versuchen dabei den Preis eines Kunstwerkes vorherzusagen, Modelle des Typs II versuchen vorherzusagen, ob das Bild effektiv verkauft wird oder nicht.
Für beide Typen von Modellen habe ich jeweils verschiedene Ansätze ausprobiert und miteinander verglichen. Von klassischen, statistischen Methoden, wie «Lasso» oder «Ridge Regression» bis hin zu grossen «Convolutional Neural Networks». Letztere sind heutzutage Standard in der Bilderkennung.
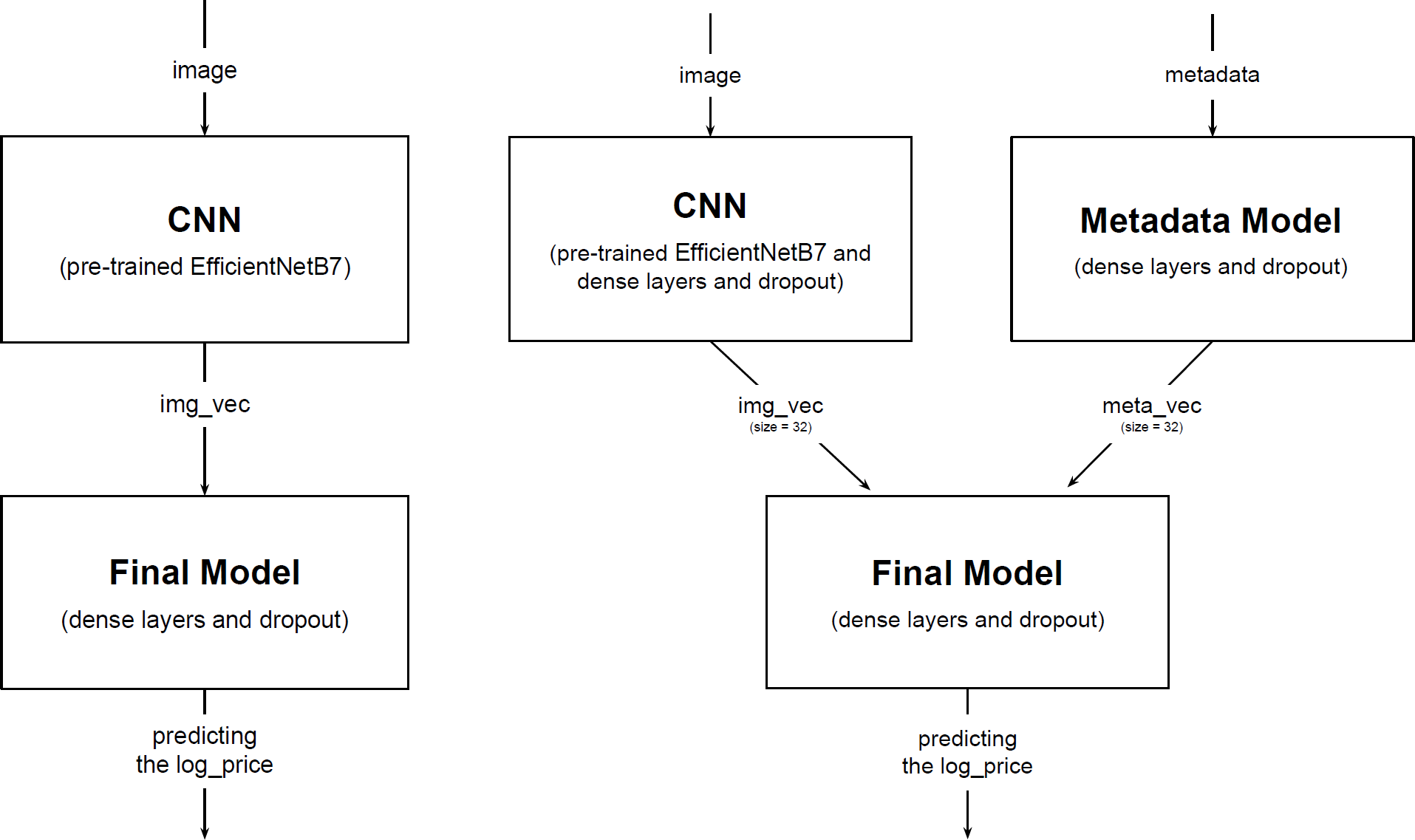
Schematisch kann man solche Modelle wie folgt darstellen. Jede Box stellt dabei eine Teilkomponente des jeweiligen Modells dar. CNN steht eben für ein solches «Convolutional Neural Network», das ein Bild als Eingabe nimmt und eine Reihe an Zahlen als Ausgabe zurückgibt. Diese Zahlen lassen sich anschliessend mit weiteren Faktoren zu einer Voraussage des Preises kombinieren.
Nun da du den Preis von Kunstwerken vorhersagen kannst, ist das der Weg zum Millionär?
Nein, ganz bestimmt nicht. Das Bewerten von Kunstwerken ist keine exakte Wissenschaft – Kunst ist subjektiv. Daher ist es auch nicht weiter verwunderlich, dass die Vorhersagen meiner Modelle teils weit daneben lagen.
Ist deine Arbeit also ein Misserfolg?
Nein, das auch nicht. Erstens habe ich persönlich während des Arbeitsprozesses extrem viel neues gelernt, dass sich so auch in weiteren Projekten anwenden lässt. Für mich ist das Abschliessen meines ersten wissenschaftlichen Papers bereits ein riesiger Erfolg. Zweitens ist ein ungenaues Modell nicht direkt mit Misserfolg gleichzusetzen. Ich bin überzeugt, dass sich die Resultate mit weiteren Daten und neuen Ansätzen noch verbessern liessen. Es bleibt ein spannendes Forschungsgebiet.
Wie würdest du weiterfahren, wenn du zusätzliche Entwicklungsressourcen hättest?
Einerseits wie bereits angesprochen mit weiteren Datensätzen. In dieser Arbeit ging es nur um Gemälde aus dem unteren Preissegment. Zudem stützt sich meine Arbeit auf eine Momentaufnahme aus dem März 2020. Im Zusammenhang mit Corona hat sich aber gerade im digitalen Kunstmarkt einiges getan. Den zeitlichen Verlauf der Kunstwerke auf der Plattform zu untersuchen, wäre sicherlich höchst spannend und aufschlussreich.
Andererseits lassen sich auch noch weitere Modelle auf die bereits vorhandenen Daten anwenden. Gerade im Bereich der Neuronalen Netzwerke hat die Auswahl und Konstruktion der Modelle eher einen künstlerischen Charakter, als deren einer streng wissenschaftlichen Vorgehensweise.
Was hat dich im Verlauf deiner Arbeit am meisten überrascht?
Die Vielseitigkeit des Themas. Kunst ist ein weiter Begriff, ebenso das Feld des Machine Learnings bzw. der Datenanalyse. Treffen die beiden aufeinander, so sind die Möglichkeiten schier unendlich.
Welche Tipps hast du für andere angehende Data Scientists?
Probieren, probieren und noch einmal probieren.
Für die Datenanalyse gibt es kein Patentrezept. Viele Zusammenhänge lassen sich nur durch intensive Auseinandersetzung mit dem Datensatz finden. Offensichtliche Zusammenhänge oder auffällige Muster stellen sich bei genauem Hinsehen oft auch als irreführend heraus. Das gleiche gilt bei der Auswahl der Modelle. Gebt daher nicht zu früh auf, Durchhaltewillen lohnt sich!