Modellvalidierung am Beispiel der Super-Bowl-Vorhersage
5. Februar 2021

Themen
Einleitung
Dieses Wochenende ist es wieder soweit. Der Super Bowl – das Finalspiel der American Football Saison – eines der grössten Einzelsportereignissen des Jahres findet in Tampa statt. Auch für die 55. Austragung dieses Events gibt es hunderte von Expertenmeinungen und Prognosen.
Auch der amerikanische Vorhersagespezialist FiveThirtyEight – ursprünglich gegründet für die Prognose von Wahlergebnisse in den USA auf Basis von aufbereiteten Umfragedaten – hat sich in den letzten Jahren neben vielen anderen Themen und Sportarten vertieft mit dem Thema „American Football“ befasst und für die Teams der NFL ein ELO-Rating-System entwickelt, das ähnlich dem im Schach und anderen Sportarten verwendeten Punktesystem entspricht.
Dabei starten alle Teams/Spieler mit der gleichen Punkteanzahl. Nach einem Spiel werden dem siegreichen Team Punkte gutgeschrieben und dem anderen Team die gleiche Anzahl Punkte abgezogen. Für weitere Begegnungen berechnen sich dann aus der Differenz der beiden aktuellen Punktestände der Teams die Wahrscheinlichkeiten für einen Sieg oder eine Niederlage. Das Modell wurde dann von Nate Silver und seinen Mitarbeitenden um diverse sportartspezifische Besonderheiten erweitert; die genauen Details sind in ihrem Methodenbeschrieb nachzulesen.
Für den Superbowl LV vom Sonntag sagt das Modell jetzt eine Gewinnwahrscheinlichkeit für die Mannschaft der Kansas City Chiefs von 53% voraus und – weil es am Schluss ja einen Sieger geben muss – für die gegnerische Mannschaft der Tampa Bay Buccaneers ein Wahrscheinlichkeit von 47%. Doch wie sind diese Wahrscheinlichkeiten genau zu interpretieren?
Vorhersage der Wahrscheinlichkeit
Wenn das Spiel 100 mal stattfinden würde, müssten gemäss dem Modell die eine Mannschaft 53 der Begegnungen gewinnen und die andere deren 47. Das Spiel findet aber nur einmal statt und am Schluss wird nur eine Mannschaft gewinnen. Um also einen Tipp abzugeben würde man einfach die Mannschaft nehmen mit über 50% Gewinnwahrscheinlichkeit und hätte dann eine bessere Chance als bei einem rein zufälligen Tipp. Also ist für das einzelne Spiel gar nicht so entscheidend, ob das Modell jetzt 70% oder 53% Gewinnwahrscheinlichkeit vorhersagt.
Wenn man sich jetzt aber überlegt, dass Modell A jedes Jahr 53% zu 47% vorhersagen würde und Modell B jedes Jahr 70% zu 30% und der Gewinner über zehn Jahre jedes Jahr wechselt, wäre rückblickend klar, dass das Modell A besser war, obwohl beide Modelle den Gewinner in genau der Hälfte der Spiele korrekt vorhergesagt haben. Modell A hat aber durch die Zahlen nahe bei 50% impliziert, dass die Entscheidung knapp sein könnte, wohingegen beim Modell B auffällt, dass mehrmals ein Team gewonnen hat, dem nur 30% Gewinnwahrscheinlichkeit zugesagt wurden.
Validerung der Vorhersagen
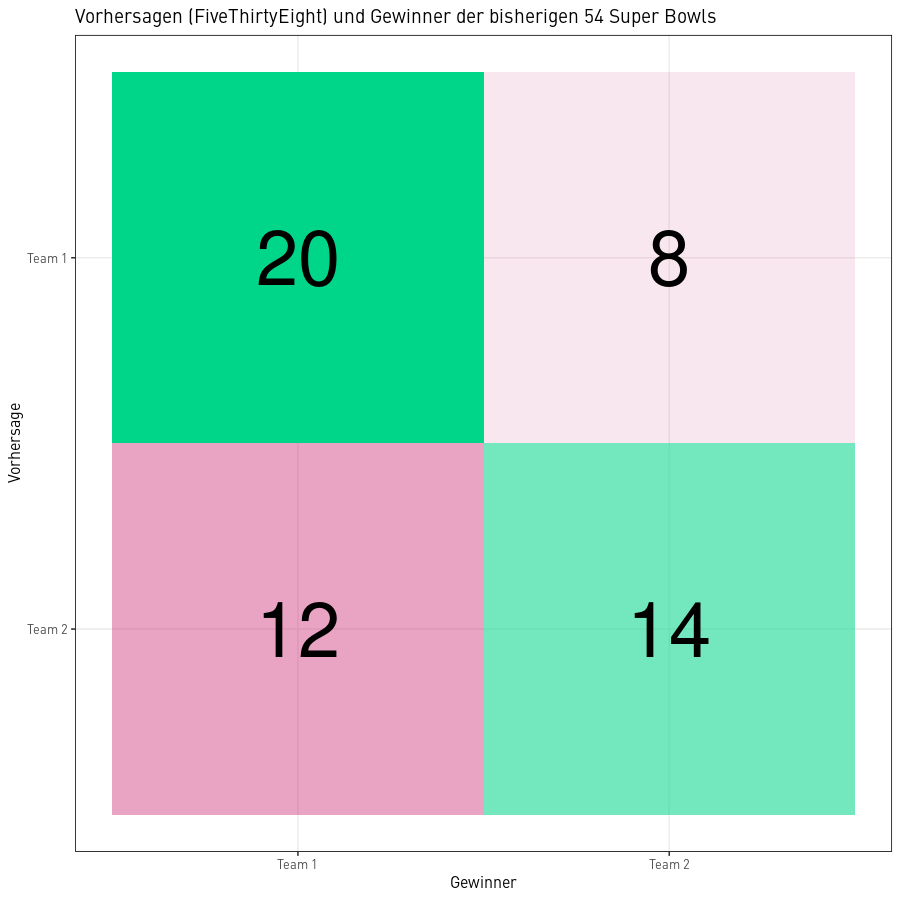
Das Modell von FiveThirtyEight liefert Vorhersagen aller bisherigen 54 Superbowls, die wir im Detail auswerten können. Wenn man immer auf das Team tippt, das eine Wahrscheinlichkeit von über 50% für den Sieg hat, wäre man in 34 Fällen korrekt gelegen und hätte 20 mal auf den falschen Sieger getippt. Bei einem rein zufälligen Tipp müsste man langfristig bei 50% landen, somit sind die rund 63% Genaugikeit des Modells schon mal deutlich besser. Aufgrund der Tatsache, dass nur die Superbowls für die Validierung benutzt und deshalb nur 54 Prognosen betrachtet werden, ist aber noch nicht klar, ob das Modell inhaltlich oder nur zufällig gut ist. Das 95%-Konfidenzintervall geht von 49% bis 76% womit noch eine Wahrscheinlichkeit von über 5% besteht, dass das Modell nur zufällig besser ist als Raten.
Natürlich kann man jetzt auch noch die „eindeutigen“ Vorhersagen anschauen, die einem Team eine Wahrscheinlichkeit von 2/3 oder mehr geben für einen Gewinn. Vom Modell, das hier angeschaut wird, wurden 12 Spiele mit Wahrscheinlichkeiten von mehr als 66.6% vorhergesagt. Aber auch davon waren 8 Vorhersagen korrekt und 4 nicht. Nur weil die vorhergesagten Wahrscheinlichkeiten grösser sind, werden die Vorhersagen nicht wesentlich treffsicherer.
Test der Modellkalibrierung
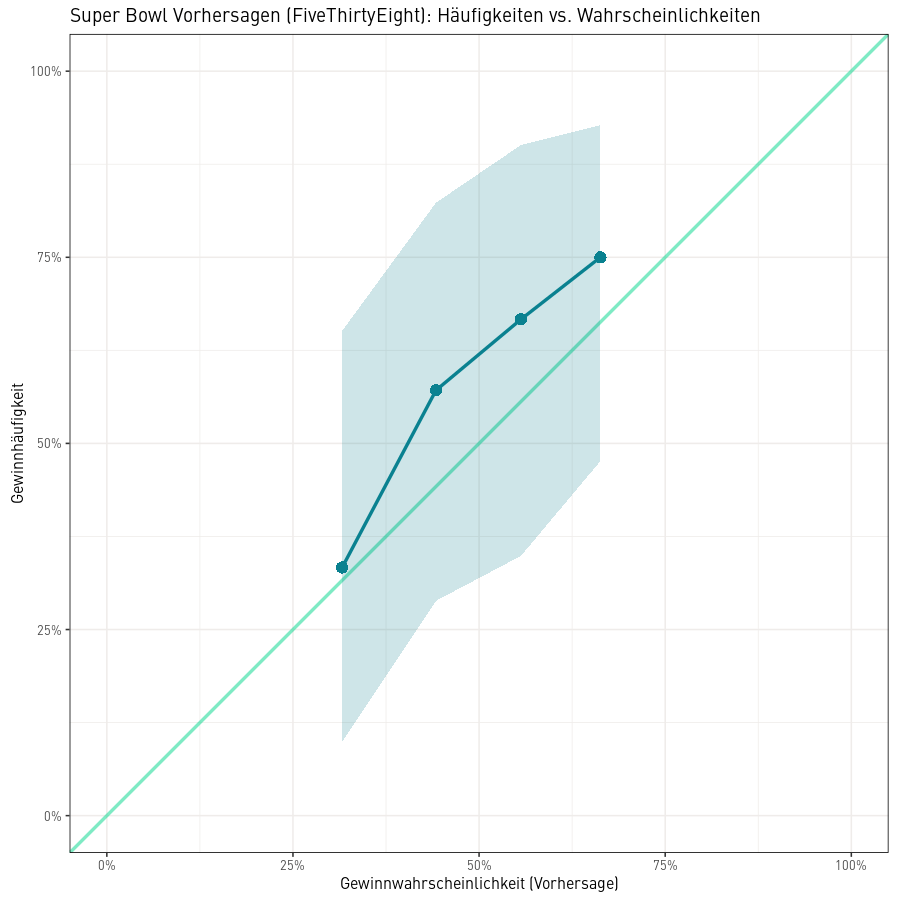
Schlussendlich möchte man ja aber wissen, ob das Modell nicht nur den Sieger richtig vorhersagt sondern langfristig auch die richtigen Wahrscheinlichkeiten angibt. Dazu werden die 54 Vorhersagen in Teilbereiche aufgetrennt betrachtet: Alle Vorhersagen mit einer Siegeswahrscheinlichkeit für Team 1 von unter 40%, alle mit 40-50%, 50-60% und alle über 60% (da sich die Siegeswahrscheinlichkeiten von Team 1 und 2 zu hundert Prozent addieren, reicht es die Analyse für ein Team durchzuführen).
In einem perfekt kalibrierten Modell würde Team 1 langfristig rund 45% der Spiele gewinnen, die mit 40-50% Gewinnwahrscheinlichkeit vorhergesagt werden und rund 55% der Spiele, die mit 50-60% Gewinnwahrscheinlichkeit vorhergesagt sind. Das heisst in der Grafik mit den vorhergesagten Wahrscheinlichkeiten und den tatsächlichen Häufigkeiten, würde das perfekte Modell genau durch eine Diagonale abgebildet. In einem sehr schlecht kalibrierten Modell ist diese Linie des Modells weit von der Diagonalen entfernt und/oder hat gar nicht die Form einer Geraden, sondern sieht z.B. mehr wie ein um 90 Grad gedrehtes „S“ aus.
Zusammenfassung
In einem gut validierten und kalibrierten Modell sollten die vorhergesagten Wahrscheinlichkeiten langfristig den tatsächlichen Häufigkeiten entsprechen. Da wir das Modell hier nur anhand von 54 Vorhersagen und Beobachtungen beurteilen, ist natürlich eine kleine, statistisch aber nicht signifikante, Abweichung der Kalibrationslinie von der Diagonalen zu beobachten. Für genauere Aussagen müssten die Vorhersagen auf allen Saisonspielen auch noch in die Analyse miteinbezogen werden; wobei ein ELO-Modell schon aufgrund der Konstruktion eine gute Kalibration aufweisen sollte.
Generell sind die Modelle für Vorhersagen von Sport-Veranstaltungen zum Glück noch nicht perfekt – wo würde dann die Spannung bleiben -, aber mindestens schon so gut wie viele Experten.