Machine Learning als Webapplikation
11. März 2019

Themen
Buzzwords wie künstliche Intelligenz (KI) und maschinelles Lernen (ML) sind in aller Munde. Unser Data Scientist erklärt mit einfachen Worten, was dahinter steckt. Trainieren Sie Ihre eigenen Modelle mit der praktischen Webapplikation Predictoor und dem Algorithmus „Random Forest“.
Was ist Machine Learning?
Können Sie den Verkaufspreis eines Einfamilienhauses vorhersagen? Welche Ihrer Kunden werden ihren Vertrag nächstens künden? Wie unterscheiden Sie zwischen verdächtigen Transaktionen und normalen Banküberweisungen? Solche Fragen führen direkt in die Welt der künstlichen Intelligenz und des maschinellen Lernens (engl. Machine Learning), wo aus Daten Informationen werden.
Der Unterbereich des überwachten Lernens (engl. Supervised Learning) beschäftigt sich mit Algorithmen, die in unzähligen Datenbeispielen Zusammenhänge zwischen einer Zielgrösse und erklärenden Variablen finden. Nach dieser Lernphase (auch Trainingsphase genannt) kann der Algorithmus die gelernten Zusammenhänge auf neue Fälle übertragen und so die Zielgrösse vorhersagen.
Variablen
Variablen erklären einen Datensatz und helfen dem Algorithmus, Zusammenhänge zu finden.

Zielvariable
Was soll vorhergesagt werden? Zum Beispiel, bei welchen Mitarbeitern ein Kündigungsrisiko besteht.
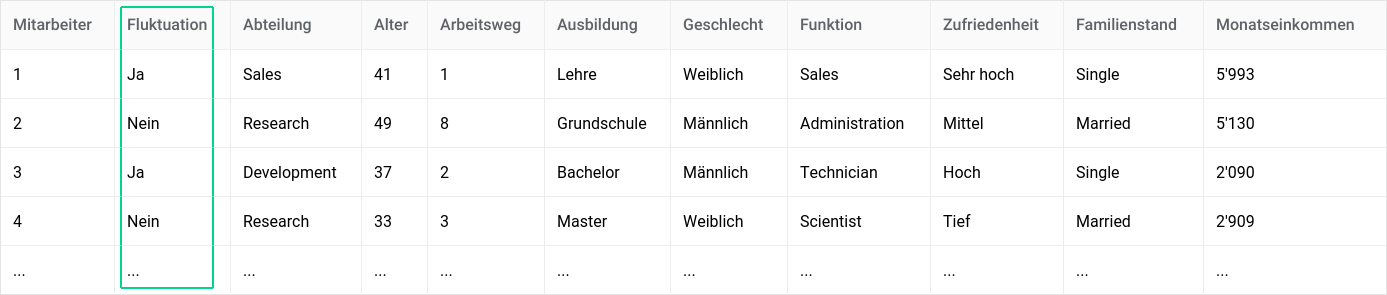
Fälle
Jede Zeile ist eine Beobachtung. Anhand dieser lernt der Algorithmus, neue Fälle vorherzusagen.

Nicht mehr nur Experten vorbehalten
Lange Zeit konnten nur Spezialisten komplexe Vorhersagemodelle entwickeln und einsetzen: Sie prüften, vervollständigten und transformierten die Eingabedaten, wählten eine passende Modellklasse, optimierten die Modellparameter und validierten die Vorhersagegenauigkeit. Mit modernen Algorithmen und sinnvollen Vorverarbeitungsschritten lässt sich dieser Prozess unterdessen weitgehend automatisieren. Die resultierenden Modelle liefern robuste und akkurate Vorhersagen, falls die Daten dies zulassen.
Gerade die Vorverarbeitungsschritte sind jedoch unerlässlich und können überaus komplex sein. Damit der Lernalgorithmus exakte Vorhersagen machen kann, ist eine strukturierte Datenbasis notwendig. Dabei sollte die Zielvariable möglichst genau definiert sein (sog. Feature Engineering).
Coming up with features is difficult, time-consuming, requires expert knowledge. ‘Applied machine learning’ is basically feature engineering.
Andrew Ng
Probieren geht über Studieren
Vielleicht verfügen auch Sie über einen Datensatz, der Ihre Produkte, Ihre Kundendaten oder beispielsweise die Angebote der Konkurrenz beschreibt. Sie möchten eine wichtige Variable dieses Datensatzes mit Hilfe der anderen Informationen vorhersagen. So könnten Sie z.B. die zukünftigen Verkaufszahlen Ihrer Produkte abschätzen, Kunden mit einem hohen Kündigungsrisiko identifizieren und kontaktieren oder das Preismodell Ihrer Konkurrenz durchleuchten.
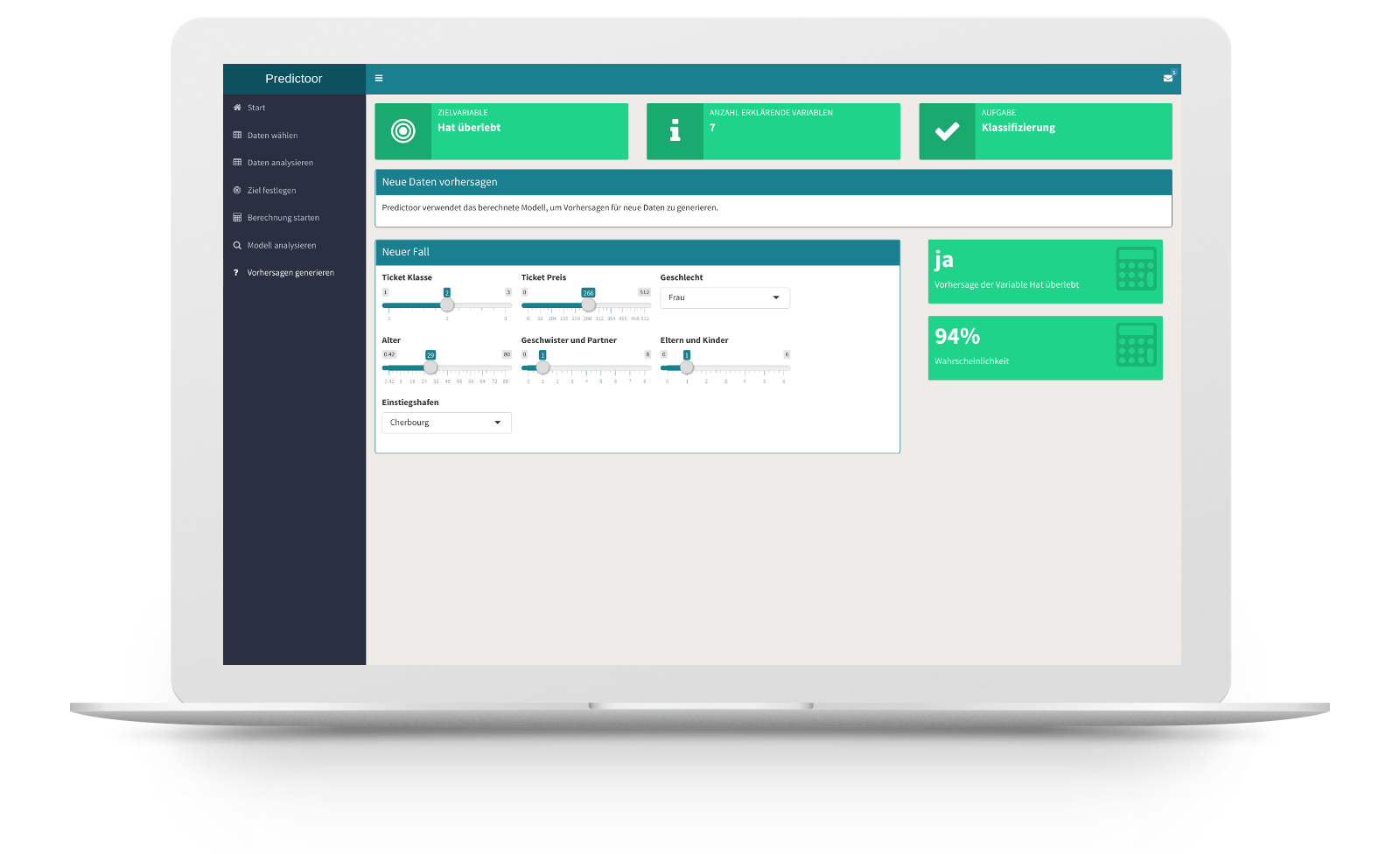
Probieren Sie es aus! Predictoor ist Ihre künstliche Intelligenz, er lernt auf Ihrem Datensatz die gewünschte Zielgrösse mit den von Ihnen gewählten Informationen vorherzusagen.
Predictoor
Predictoor prüft zuerst den Umfang und die Vollständigkeit Ihres Datensatzes und entscheidet, welche Variablen für die Modellierung geeignet sind. Predictoor entscheidet sich aufgrund der gewählten Zielgrösse automatisch für ein passendes Regressions- oder Klassifikationsmodell (Vorhersagen von Zahlenwerten wie z.B. Preisen oder Vorhersagen von Kategorien wie z.B. «kündigt» / «kündigt nicht»). Während der Lernphase optimiert er die Modellparameter und prüft die Modellgüte, indem er seine Vorhersagen für zuvor ausgeschlossene Datenpunkte mit den tatsächlichen Werten vergleicht (dieser wichtige Check wird Kreuzvalidierung genannt). Die Vorhersagegenauigkeit und die Wichtigkeit der einzelnen erklärenden Variablen zeigt er Ihnen verständlich auf. Schliesslich können Sie mit dem trainierten Modell Vorhersagen für neue Fälle generieren.
Ein Random Forest steckt dahinter
Predictoor lernt aktuell mit einem bekannten und potenten Algorithmus, dem Random Forest (entwickelt von Leo Breiman im Jahr 1999). Dabei bildet er unzählige Varianten von leicht durch Zufall beieinflussten Entscheidungsbäumen. Für eine Vorhersage werden die Resultate aller einzelnen Bäume gemittelt und weil viele Bäume einen Wald bilden, entstand der Name Random Forest.
Sie können Predictoor auch ohne eigene Daten kennenlernen. Verschiedene Beispieldatensätze stehen bereit, damit Sie Ihre ersten Modelle trainieren können. Lassen Sie Predictoor die Überlebenswahrscheinlichkeit von Titanic-Passagieren, Hauspreise oder die Qualität von Weinen vorhersagen!
Zusätzliche Informationen
Erkunden Sie die Möglichkeiten moderner Algorithmen auf Ihren Datensätzen! Gerne unterstützen wir Sie dabei mit zusätzlichen Daten, Aufbereitungsschritten oder spezifisch optimierten Modellen, damit auch aus Ihren Daten Informationen werden.